A learner's guide to the architecture changing how large language models are served
For the last two years, most of the AI infrastructure conversation has centered around one question: who has enough GPUs?
That question still matters. But it is no longer sufficient.
As large language models move from experimentation into production, the real bottleneck is shifting from raw GPU availability to how intelligently those GPUs are used. The next frontier in inference infrastructure is not simply putting a model on a GPU and serving requests. It is designing an inference system that understands the different phases of an LLM request, places each phase on the right hardware, manages memory as a first-class resource, and optimizes for cost, latency, and throughput simultaneously.
That is where disaggregated inference comes in.
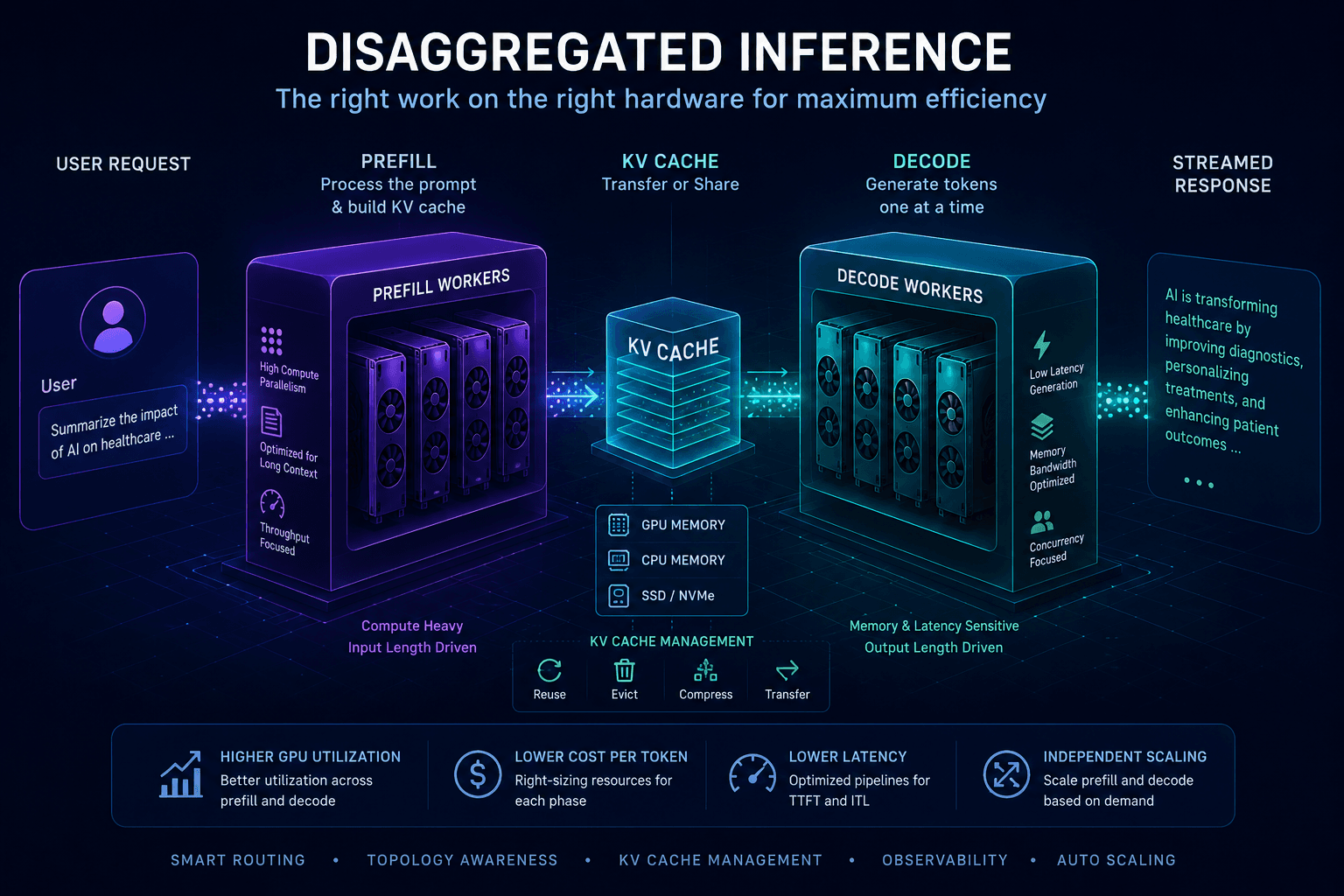
Disaggregated inference is one of the most important infrastructure patterns emerging in large-scale LLM serving. At a high level, it means separating parts of the inference workload that were traditionally handled together. The most important version of this is prefill/decode disaggregation.
In simple terms:
- Prefill processes the input prompt and builds the KV cache.
- Decode generates the output tokens one at a time.
Historically, both phases ran on the same GPU worker. But as models get larger, context windows get longer, and inference traffic becomes more diverse, that approach becomes economically inefficient.
The core idea behind disaggregated inference is simple:
Not every part of LLM inference stresses hardware in the same way. So why force every part of the workload to run on the same kind of infrastructure?
The Traditional Model: One Worker Does Everything
In a traditional inference setup, a user sends a request to an LLM endpoint. A GPU worker receives the request, processes the prompt, generates the output, and returns the response.
The flow looks like this:
Request → Prefill → KV Cache Creation → Decode → Response
This is simple and works well for many workloads. If the model is small, the context length is short, traffic is predictable, and latency requirements are manageable, there may be no need to complicate the architecture.
But LLM inference is becoming much more demanding.
Modern production workloads include long-context RAG, coding assistants, legal document review, financial research, multi-agent workflows, customer support copilots, summarization systems, and reasoning-heavy applications. These workloads do not have uniform request shapes. Some requests have short prompts and long outputs. Others have extremely long prompts and short outputs. Some require low time-to-first-token. Others require high sustained token generation. Some reuse the same context repeatedly. Others are completely cold requests.
When all of these workloads are forced through the same homogeneous serving path, infrastructure efficiency starts to break down.
Why Prefill and Decode Are Different
To understand disaggregated inference, you first need to understand why prefill and decode are fundamentally different.
Prefill: The Prompt Processing Phase
Prefill happens when the model processes the input prompt. If the user sends a 2,000-token prompt, the model processes those 2,000 input tokens and creates a KV cache that can be used during generation.
Prefill is usually more parallelizable. The model can process many prompt tokens together, which makes prefill more compute-heavy. Long-context workloads make prefill particularly expensive because the model must process a large amount of input before generating the first token.
Examples of prefill-heavy workloads include:
- Long-document summarization
- Legal contract review
- Financial research over large documents
- Enterprise RAG with many retrieved chunks
- Codebase analysis with large context windows
In these workloads, the user may only want a short answer, but the model has to process a huge amount of context before producing it.
Decode: The Token Generation Phase
Decode is different. Once the prompt has been processed, the model generates output tokens one at a time. Each new token depends on the previous tokens, so decode is much more sequential.
Decode is often sensitive to:
- Memory bandwidth
- KV-cache access
- Active sequence count
- Output length
- Inter-token latency
- Tail latency under concurrency
Examples of decode-heavy workloads include:
- Chatbots producing long answers
- Coding assistants generating long code blocks
- Agentic systems with multi-step reasoning
- Creative writing
- Long-form report generation
In these workloads, the prompt may not be extremely large, but the model may spend a long time generating output tokens.
This difference matters because prefill and decode create different infrastructure bottlenecks.
Prefill is usually driven by input length and compute throughput. Decode is driven by concurrency, memory bandwidth, output length, and KV-cache residency.
That is the fundamental reason disaggregated inference exists.
What Is the KV Cache, and Why Does It Matter?
The KV cache is one of the most important concepts in LLM inference.
During prefill, the model computes key and value tensors used by the attention mechanism. These are stored in the KV cache so that the model does not need to recompute the entire prompt during every decode step.
This makes generation much faster. But it also creates a new infrastructure problem: the KV cache can become very large.
A useful mental model:
- A 70B model in BF16 requires roughly 140GB just for model weights.
- For a Llama 3.1 70B model at 128K context, the KV cache adds about 40GB per active sequence, which is more than the model weights themselves at INT4 quantization.
- Run 4 concurrent requests at 128K context and you need around 160GB just for the cache, which exceeds even an H200's 141GB of VRAM.
- At very long context lengths, the KV cache can become more important than the model weights.
This is why disaggregated inference is not just about compute. It is about memory placement, cache movement, cache reuse, and scheduling.
In a disaggregated architecture, the prefill worker creates the KV cache, but the decode worker needs access to it. That means the system must either transfer the KV cache, expose it remotely, colocate workers intelligently, or route requests based on cache locality.
This is the hard part.
If KV-cache transfer is slow, disaggregation can make performance worse. If KV-cache movement is fast and well-orchestrated, disaggregation can improve utilization, latency, and cost simultaneously.
What Disaggregated Inference Actually Looks Like
In a basic disaggregated architecture, the flow becomes:
Request → Prefill Worker → KV Cache Transfer/Exposure → Decode Worker → Response
Instead of one GPU worker doing everything, there are separate pools:
- Prefill workers optimized for prompt processing
- Decode workers optimized for token generation
- Router/scheduler that decides where requests go
- KV-cache transfer path that moves or exposes inference state
- Observability layer tracking latency, utilization, cache pressure, and throughput
The system can then scale prefill and decode independently.
For example, if traffic suddenly includes many long documents, the system may need more prefill capacity. If users are asking for long generated reports, the system may need more decode capacity. In a monolithic architecture, both situations require scaling the same kind of GPU worker. In a disaggregated architecture, the system can scale the bottleneck phase more precisely.
Example 1: Long-Document Legal Review
Imagine a legal AI assistant reviewing a 100-page contract.
The user asks:
"Summarize the termination clauses and identify unusual obligations."
The input is long. The output may be relatively short.
This is a classic prefill-heavy workload. The model must process a large amount of contract text before producing a response. The expensive part is not necessarily generating the final answer; it is reading and encoding the input context.
In a traditional inference setup, the same GPU worker handles both the long prefill and the short decode. While it is processing the long prompt, it may block or delay other requests. If many users submit long documents simultaneously, time-to-first-token can degrade quickly.
In a disaggregated setup, long-context prefill can be routed to dedicated prefill workers. Decode workers can remain focused on active generation for other users. This reduces interference between long prompt processing and ongoing token generation.
The benefit is not just performance. It is operational control. The infrastructure team can now see whether the bottleneck is prefill or decode and scale the right pool.
Example 2: Customer Support Chatbot
Now consider a customer support chatbot.
Most requests are short:
"Where is my order?" "Can I reset my password?" "Explain the refund policy."
The input may be 500 to 2,000 tokens. The output may be 200 to 800 tokens. The workload has high concurrency, but context length is moderate.
This may not need disaggregated inference initially. A well-optimized inference server with continuous batching, caching, autoscaling, and good model selection may be enough.
This is an important point: disaggregated inference is not automatically better for every workload.
For small models, short prompts, low concurrency, or simple chatbot workloads, the overhead of separating prefill and decode may not be worth it. The extra complexity of KV-cache transfer, topology-aware routing, and multi-pool scheduling may outweigh the benefits.
The right infrastructure decision depends on workload shape.
Example 3: Coding Assistant
A coding assistant is more complex.
A developer may ask:
"Given this repository context, modify this API handler and update the unit tests."
The input could include many files, documentation, stack traces, and prior conversation history. The output may also be long because the model generates code, explanations, and test cases.
This workload stresses both prefill and decode.
The prefill phase is expensive because the model needs to process a large codebase context. The decode phase is also expensive because the model may generate thousands of tokens of code.
This is where disaggregated inference becomes especially interesting. The platform may need to optimize long-context prefill, keep KV cache available for follow-up turns, and support long decode sessions without starving other requests.
For coding agents, cache reuse also becomes critical. If the same repository context is reused across multiple requests, the system can benefit from KV-aware routing or prefix caching. Instead of recomputing the same context repeatedly, the platform can route requests to workers that already have relevant cache state or use a cache management layer to reuse prior computation.
In this world, the inference platform starts to look less like a simple API endpoint and more like a distributed operating system for tokens, memory, and accelerators.
Example 4: Enterprise RAG
Enterprise RAG is one of the most common real-world examples.
A user asks a question. The system retrieves documents from a vector database, inserts those documents into the prompt, and sends the full context to the model.
The actual user question may be short, but the final prompt may be long because it includes retrieved context.
For example:
- User question: 50 tokens
- Retrieved documents: 20,000 tokens
- Model output: 500 tokens
This is prefill-heavy. The model spends most of its work reading retrieved context.
As context windows move from 8K to 32K to 128K and beyond, this pattern becomes more expensive. Many enterprise AI applications are quietly becoming long-context inference applications.
In a disaggregated architecture, these RAG workloads can be routed differently from short chat workloads. Long prompts can go to prefill-optimized workers. Decode capacity can be protected for active generation. The platform can track whether retrieved context size is driving cost and latency.
This also changes how application teams should think about RAG. It is not enough to ask, "Can the model fit the context?" The better question is, "What does this context do to prefill cost, KV-cache size, time-to-first-token, and serving efficiency?"
Example 5: Multi-Agent Workflows
Agentic AI makes this even more interesting.
In a multi-agent system, several agents may operate over the same context. One agent may plan, another may retrieve, another may reason, another may write, and another may verify. These agents may repeatedly use overlapping prompt prefixes.
This creates a lot of redundant prefill work.
If every agent repeatedly processes the same context independently, infrastructure cost can grow quickly. Disaggregated inference, prefix caching, and KV-cache-aware routing can help reduce redundant computation.
This is why the future of inference infrastructure will not just be about faster token generation. It will be about understanding workload structure. Agentic systems create repeated context, tool pauses, long-running sessions, and irregular token patterns. The inference layer must become more stateful, more cache-aware, and more workload-aware.
Homogeneous vs. Disaggregated Accelerator Architectures
Most organizations start with homogeneous infrastructure. That means the same type of accelerator handles most inference workloads.
This has real advantages:
- Simpler scheduling
- Easier debugging
- Fewer model compatibility issues
- More fungible capacity
- Simpler procurement
- Easier operational playbooks
For many teams, homogeneous GPU infrastructure is the right starting point.
But at scale, homogeneous infrastructure can become inefficient. If prefill and decode need different resource profiles, using the same accelerator pool for both may create stranded capacity.
This leads to two forms of disaggregation.
1. Logical Disaggregation on the Same Hardware
This is the first step for many teams. The organization may still use the same GPU type, but it separates prefill and decode into different worker pools.
This allows independent scaling without introducing heterogeneous hardware complexity.
2. Hardware-Level Disaggregation
The more advanced version uses different hardware for different phases. For example, one accelerator type may handle prefill while another handles decode.
This is harder to operate but potentially more powerful. If prefill is compute-heavy and decode is memory-bandwidth-sensitive, then different hardware profiles may make economic sense.
Over time, we should expect more experimentation here. The future may include inference systems where GPUs, custom accelerators, CPUs, DRAM, SSDs, and high-speed interconnect all participate in serving one model request.
The Software Requirements
Disaggregated inference is primarily a software problem.
The hardware matters, but the system only works if the software can coordinate the full inference lifecycle.
The required software layers include:
1. Phase-Aware Scheduler
The scheduler must understand the difference between prefill and decode. Standard infrastructure schedulers usually think in terms of containers, nodes, CPU, memory, and GPU allocation. LLM inference needs something more specific.
The scheduler needs to understand:
- Input length
- Output length estimate
- Model size
- KV-cache pressure
- Queue depth
- Prefix cache hits
- Worker load
- Latency SLOs
- Hardware topology
2. KV-Cache Manager
The KV cache must be treated as a first-class resource.
The system needs to know where KV cache is created, where it lives, whether it can be reused, whether it should be transferred, and when it should be evicted.
Without KV-cache management, disaggregated inference becomes fragile.
3. Low-Latency Transfer Layer
If prefill and decode happen on different workers, the decode worker needs access to the KV cache.
That requires a fast transfer path. In high-performance environments, this may involve NVLink, InfiniBand, RDMA, UCX, NVIDIA's NIXL library, or other high-speed communication layers.
This is one of the most important practical constraints. If KV transfer is slow, disaggregation loses.
4. Topology-Aware Routing
Not all workers are equally close to each other.
A prefill worker and decode worker on the same node may have very different performance from workers separated across racks or availability zones. The router must understand topology so it can avoid expensive cache movement when possible.
5. Observability
You cannot manage what you cannot measure.
A disaggregated inference stack should track:
- Time to first token
- Inter-token latency
- End-to-end latency
- P95/P99 latency
- Tokens per second
- GPU utilization
- HBM utilization
- KV-cache memory pressure
- Prefill queue depth
- Decode queue depth
- Cache hit rate
- KV transfer latency
- Cost per million tokens
Without these metrics, the team will not know whether disaggregation is helping or hurting.
Important Numbers to Keep in Mind
For readers new to this topic, here are useful orders of magnitude.
Model Size
A 70B parameter model requires roughly:
- 140GB in BF16/FP16
- 70GB in FP8/INT8
- 35GB in INT4
That means a 70B model is already a multi-GPU or high-memory serving problem unless heavily optimized.
Context Length
Common context tiers:
- 4K to 8K tokens: basic chatbot
- 16K to 32K tokens: enterprise RAG and coding assistant baseline
- 64K to 128K tokens: long-document workflows
- 200K to 400K tokens: frontier long-context workloads
- 1M tokens: extreme long-context use cases
Long context is one of the biggest drivers of prefill cost and KV-cache growth.
GPU Memory
Useful memory numbers:
More memory helps, but it does not eliminate the need for better scheduling. As context windows grow, memory pressure grows with them.
KV Cache
For a Llama 3.1 70B model at 128K context, the KV cache is roughly 40GB per active sequence. At 1M context, KV cache can become hundreds of GB. Run several concurrent long-context sequences and the KV cache alone can dwarf the model weights.
This is why KV-cache-aware infrastructure matters.
Who Is Working on This?
Several public examples show where the market is heading.
Moonshot AI's Mooncake is one of the clearest public examples of KV-cache-centric disaggregated serving. Mooncake is the platform that runs Kimi, Moonshot AI's LLM service. It separates prefill and decode clusters and treats KV cache as a central scheduling and memory-management problem, even pooling CPU, DRAM, SSD, and RDMA resources across the cluster into a unified cache. The published Mooncake paper reports that the system handles 59 to 498 percent more requests on real production traces compared to baseline methods, with the platform operational across thousands of nodes processing over 100 billion tokens per day.
NVIDIA Dynamo is a major software stack aligned with this shift. It provides disaggregated serving patterns, prefill and decode worker pools, KV transfer via the NIXL library, topology-aware routing, an SLO planner, and integration paths with inference backends including vLLM, SGLang, and TensorRT-LLM. Public benchmarks cite up to 7x higher throughput compared to monolithic serving on favorable workloads.
Red Hat's llm-d is another important ecosystem effort. Built in collaboration with IBM, Google, and the broader AI infrastructure community, it is Kubernetes-native and focuses on distributed inference, KV-aware routing, disaggregated prefill and decode, and cloud-native deployment. Recent benchmarks show cache hit rates above 87 percent on representative workloads.
Alibaba's RTP-LLM is the inference engine developed by Alibaba's Foundation Model Inference Team. It is used widely across Alibaba Group, supporting LLM services for Taobao, Tmall, Idlefish, Cainiao, Amap, Ele.me, AliExpress, and Lazada. The project represents the scale of production LLM serving inside one of the largest commerce platforms in the world.
Other relevant projects include vLLM, which now supports experimental disaggregated prefill with connectors for NIXL and Mooncake; SGLang, which provides its own disaggregated prefill-decode architecture; LMCache for distributed cache management; DeepSeek's published inference system, which leverages disaggregation aggressively; and academic systems like DistServe and Splitwise that helped establish the design patterns.
The broader direction is clear: inference infrastructure is moving from simple model hosting to full-stack serving optimization.
When Disaggregated Inference Helps
Disaggregated inference is most useful when:
- Prompts are long
- Output lengths are variable
- Traffic is high concurrency
- Workloads have mixed request shapes
- KV cache is large
- Prefix/cache reuse is meaningful
- Latency SLOs are strict
- GPU utilization is uneven
- Cost per token matters
- Different phases benefit from different hardware profiles
In other words, disaggregation helps when the serving system has become complex enough that one-size-fits-all GPU hosting is no longer efficient.
When It May Not Help
Disaggregated inference may not be the right answer when:
- Models are small
- Prompts are short
- Traffic is low
- Workload shape is predictable
- KV transfer is slow
- Observability is weak
- Operational complexity is not justified
- A simple inference stack already meets cost and latency goals
This matters because disaggregation is not magic. It introduces complexity. It requires better scheduling, better networking, better cache management, and better observability. Industry benchmarks suggest that for workloads outside the conditions disaggregation is designed for, performance can actually degrade by 20 to 30 percent due to KV transfer overhead.
The right question is not, "Should we disaggregate?" The right question is:
"Where is our actual bottleneck — prefill, decode, memory, cache transfer, network, batching, or scheduling?"
Only after answering that question should a team decide whether disaggregation is worth it.
The Business Case
The business case for disaggregated inference is straightforward: lower cost per token while maintaining or improving latency.
For model providers, hyperscalers, neoclouds, and large AI application companies, inference is becoming a recurring margin problem. Training is expensive, but inference is continuous. Every user request consumes compute, memory, and network resources.
If disaggregation improves accelerator utilization, reduces overprovisioning, and increases tokens served per dollar of infrastructure, it directly improves gross margin. Published gains are substantial: Mooncake reports up to 498 percent increases in effective request capacity on real workloads; Dynamo benchmarks show up to 7x throughput improvements on favorable scenarios. Even with conservative discounting for vendor enthusiasm and workload variability, these numbers materially change unit economics.
For hyperscalers and cloud providers, the decision is even more strategic. They need to support many models, many customers, many hardware types, and unpredictable demand patterns. Disaggregation gives them a path to better fleet utilization, but it also introduces operational complexity.
For enterprises, the near-term implication is different. Most enterprises will not build a Mooncake-like architecture themselves. But they should understand the pattern because it will affect cloud pricing, latency, model selection, vendor differentiation, and the economics of long-context AI applications.
The Future: Inference as an Operating System
The first wave of generative AI infrastructure was about training capacity. The second wave was about getting access to GPUs. The wave now beginning is about inference efficiency, and disaggregated serving is its earliest visible signal.
As AI applications become more agentic, long-context, multimodal, and production-critical, inference will become a full-stack systems problem. The winning platforms will not simply run models. They will intelligently manage:
- Routing
- Batching
- Prefill
- Decode
- KV cache
- Memory hierarchy
- Interconnect
- Hardware placement
- Autoscaling
- Cost per token
- Latency SLOs
The market is moving from "host this model on a GPU" to "operate an AI factory where every token, every cache block, every accelerator, and every millisecond is optimized."
That is a very different world.
Frequently Asked Questions
What is disaggregated inference?
Disaggregated inference is an LLM serving architecture where different parts of the inference workload are separated and optimized independently. The most common form is prefill/decode disaggregation, where prompt processing and token generation run on separate worker pools.
What is prefill?
Prefill is the phase where the model processes the input prompt and creates the KV cache. It is heavily affected by input length and context size, and it is usually compute-bound.
What is decode?
Decode is the phase where the model generates output tokens one at a time. It is heavily affected by output length, concurrency, memory bandwidth, and KV-cache access, and it is usually memory-bandwidth-bound.
Why separate prefill and decode?
Because they have different infrastructure characteristics. Prefill is often compute-heavy and parallelizable. Decode is sequential, memory-sensitive, and latency-sensitive. Separating them allows each phase to scale and optimize independently.
What is the KV cache?
The KV cache stores intermediate attention state from the prompt so the model does not need to recompute the entire context during generation. It improves performance but can consume significant memory. For a Llama 3.1 70B model at 128K context, the KV cache is around 40GB per active sequence.
Why is KV-cache transfer hard?
In disaggregated inference, the prefill worker may create the KV cache while the decode worker needs to use it. Moving or exposing that cache quickly is difficult, especially across nodes. If KV transfer is slow, the benefits of disaggregation can disappear.
What is NIXL?
NIXL, the NVIDIA Inference Xfer Library, is the low-latency transfer layer used by NVIDIA Dynamo to move KV cache directly between the VRAM of prefill and decode workers over the fastest available transport, typically NVLink within a node or InfiniBand across nodes.
What is Mooncake?
Mooncake is the serving platform for Kimi, the LLM service from Moonshot AI. It uses a KVCache-centric disaggregated architecture that separates prefill and decoding clusters and pools the CPU, DRAM, SSD, and RDMA resources of the cluster into a unified KV cache.
What is NVIDIA Dynamo?
Dynamo is NVIDIA's open-source distributed inference framework for disaggregated serving. It provides prefill and decode worker pools, KV-aware routing, the NIXL transfer library, an SLO planner, and integration with vLLM, SGLang, and TensorRT-LLM.
What is llm-d?
llm-d is a Kubernetes-native distributed inference framework developed by Red Hat in collaboration with IBM, Google, and the broader AI infrastructure community. It provides KV-cache aware routing, disaggregated prefill and decode, and a vLLM-optimized inference scheduler.
Does disaggregated inference require different hardware?
Not necessarily. Many systems start with logical disaggregation using the same GPU type for both prefill and decode. More advanced systems may use different hardware profiles for each phase.
Is disaggregated inference only for hyperscalers?
Today, it is most relevant for hyperscalers, model providers, neoclouds, and high-scale AI application companies. Most enterprises will consume this capability through cloud platforms or managed inference providers rather than building it themselves.
When should a company consider disaggregated inference?
A company should consider it when long context, high concurrency, variable output lengths, strict latency SLOs, or poor GPU utilization make monolithic inference serving inefficient.
When should a company avoid disaggregated inference?
A company should avoid it when workloads are small, predictable, short-context, or already well served by a simpler inference stack. Disaggregation adds complexity and should be justified by measured bottlenecks.
What metrics matter most?
The most important metrics are time-to-first-token, inter-token latency, P95/P99 latency, tokens per second, GPU utilization, HBM usage, KV-cache pressure, cache hit rate, KV transfer latency, and cost per million tokens.
Is this the future of inference?
For high-scale LLM serving, yes. The market is clearly moving toward more phase-aware, cache-aware, and hardware-aware inference systems. But for smaller workloads, simpler serving architectures will continue to be sufficient.
Final Takeaway
Disaggregated inference is not just another optimization technique. It represents a shift in how we think about LLM infrastructure.
The old model was simple:
Put the model on a GPU and serve requests.
The new model is more sophisticated:
Understand the workload, separate the phases, manage memory intelligently, route based on cache and topology, and optimize every token for cost and latency.
As context windows grow, inference traffic scales, and AI agents become more common, this shift will become increasingly important.
The companies that win in AI infrastructure will not only have access to hardware. They will know how to use that hardware with surgical precision.
That is the real promise of disaggregated inference.
Read next: Disaggregated inference is about separating the phases of serving. The companion piece, The Hidden Memory Layer Behind Long-Context AI, goes deeper on the KV cache itself — how context state is stored, reused, compressed, and governed once you start serving long-context workloads at scale.


